Query Data in a Graph Model
As you will see in this section, the data model we use determines the ease with which we can query for different types of data. The more your app relies on queries about the relationships between different types of data, the more you will benefit from querying data using a graph data model.
In a graph data model, each record (i.e., a person, post or comment) is stored as a data object (sometimes also called a node). In the example social media app described in this tutorial, we have objects for individual people, posts, and comments.
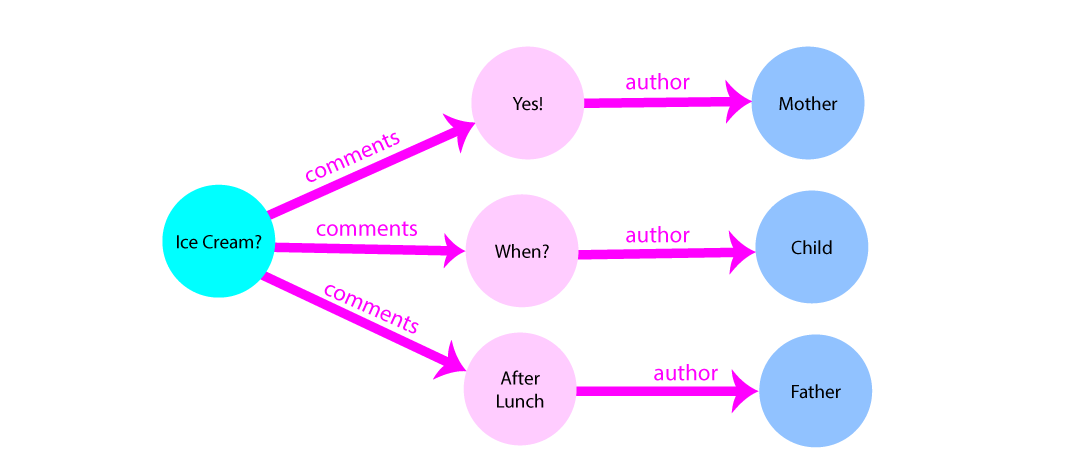
When data is requested from the graph, a root function determines which nodes are selected for the starting points. This root function will use indexes to determine which nodes match quickly. In our app example, we want to start with the root being the post with the title “Ice Cream?”. This type of lookup will evoke an index on the post’s title, much like indexes work in a relational model. The indexes at the root of the graph use the full index tree to find the data.
Connecting edges together to form a connected graph is called traversal. After
arriving at our post, “Ice Cream?”, we traverse the graph to arrive at the post’s comments.
To find the post’s author, we traverse the next step to arrive
at the people who authored the comment. This process follows the natural progression of
related data, and graph data models allow us to query our data to follow this
progression efficiently.
What do we mean by efficiently? A graph data model lets you traverse from one node to a distantly-related node without the need for anything like pivot tables. This means that queries based on edges can be updated easily, with no need to change the schema to support new many-to-many relationships. And, with no need to build tables specifically for query optimization, you can adjust your schema quickly to accommodate new types of data without adversely impacting existing queries.
A feature of a graph model is that related edges can be filtered anywhere within
the graph’s traversing. When you want to know the most recent
comment on your post or the last person to like the comment, filters
can be applied to the edge.
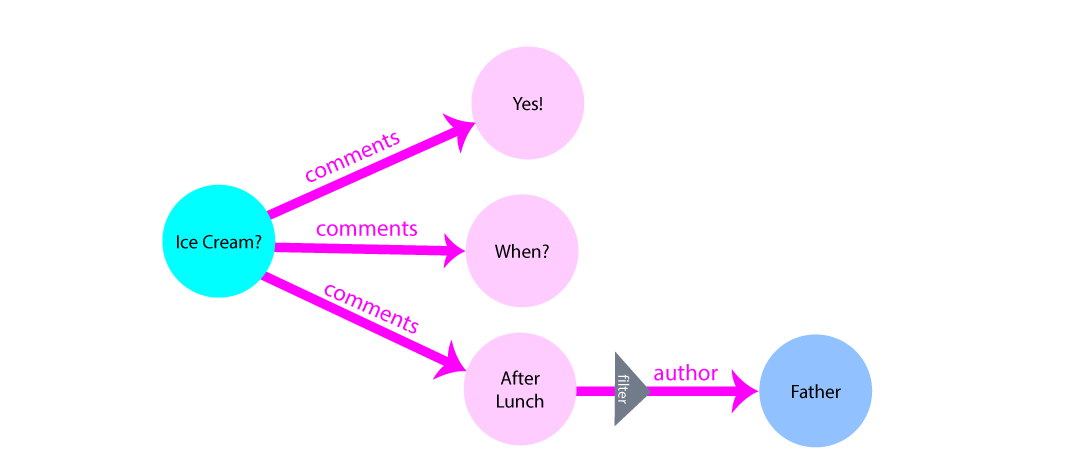
When filters get applied along an edge, only the nodes that match the edge are filtered - not all of the nodes in the graph. Applying this logic reduces the size of the graph and makes index trees smaller. The smaller an index tree is, the faster that it can be resolved.
In a graph model, data is returned in an object-oriented format. Any related data is joined to its parent within the object in a nested structure.
{
"title": "IceCream?",
"comments": [
{
"title": "Yes!",
"author": {
"name": "Mother"
}
},
{
"title": "When?",
"author": {
"name": "Child"
}
},
{
"title": "After Lunch",
"author": {
"name": "Father"
}
},
]
}
This object-oriented structure allows data to be joined without duplication.